Databricks-Certified-Data-Engineer-Associate Exam Dumps - Databricks Certified Data Engineer Associate Exam
Searching for workable clues to ace the Databricks Databricks-Certified-Data-Engineer-Associate Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s Databricks-Certified-Data-Engineer-Associate PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
A data engineer needs to determine whether to use the built-in Databricks Notebooks versioning or version their project using Databricks Repos.
Which of the following is an advantage of using Databricks Repos over the Databricks Notebooks versioning?
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL. The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which of the following changes will need to be made to the pipeline when migrating to Delta Live Tables?
A data engineer is working on a Databricks project that utilizes cloud storage. The data engineer wants to load several json files from containers on a storage account as soon as the file arrives within the storage account.
Which syntax should the data engineer follow to first load the files into a dataframe and check that it is working as expected using Python?
A data engineer has been given a new record of data:
id STRING = 'a1'
rank INTEGER = 6
rating FLOAT = 9.4
Which of the following SQL commands can be used to append the new record to an existing Delta table my_table?
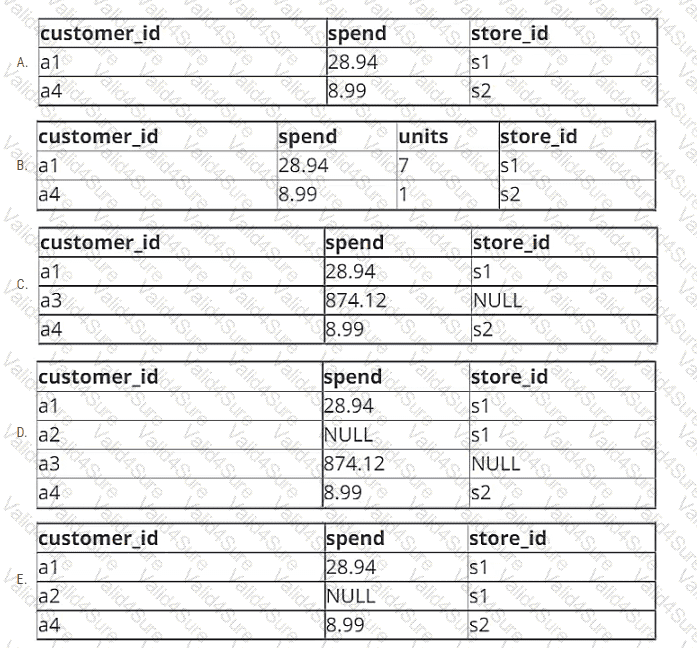
A data engineer is working with two tables. Each of these tables is displayed below in its entirety.

The data engineer runs the following query to join these tables together:

Which of the following will be returned by the above query?
A data engineer is maintaining an ETL pipeline code with a GitHub repository linked to their Databricks account. The data engineer wants to deploy the ETL pipeline to production as a databricks workflow.
Which approach should the data engineer use?
Which query is performing a streaming hop from raw data to a Bronze table?
A)

B)

C)

D)
