Databricks-Certified-Data-Engineer-Associate Exam Dumps - Databricks Certified Data Engineer Associate Exam
Searching for workable clues to ace the Databricks Databricks-Certified-Data-Engineer-Associate Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s Databricks-Certified-Data-Engineer-Associate PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
A data engineer wants to create a new table containing the names of customers who live in France.
They have written the following command:
CREATE TABLE customersInFrance
_____ AS
SELECT id,
firstName,
lastName
FROM customerLocations
WHERE country = ’FRANCE’;
A senior data engineer mentions that it is organization policy to include a table property indicating that the new table includes personally identifiable information (Pll).
Which line of code fills in the above blank to successfully complete the task?
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which change will need to be made to the pipeline when migrating to Delta Live Tables?
A data engineer needs to parse only png files in a directory that contains files with different suffixes. Which code should the data engineer use to achieve this task?
A)
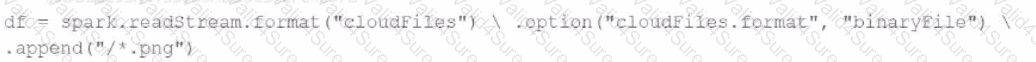
B)

C)
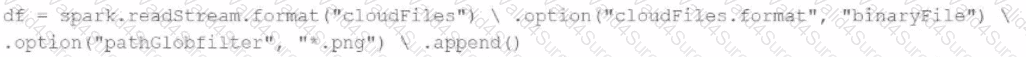
D)

A data engineer needs to conduct Exploratory Data Analysis (EDA) on data residing in a database within the company’s custom-defined cloud network. The data engineer is using SQL for this task.
Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
A data engineer needs to use a Delta table as part of a data pipeline, but they do not know if they have the appropriate permissions.
In which location can the data engineer review their permissions on the table?
A single Job runs two notebooks as two separate tasks. A data engineer has noticed that one of the notebooks is running slowly in the Job’s current run. The data engineer asks a tech lead for help in identifying why this might be the case.
Which of the following approaches can the tech lead use to identify why the notebook is running slowly as part of the Job?
A new data engineering team has been assigned to work on a project. The team will need access to database customers in order to see what tables already exist. The team has its own group team.
Which of the following commands can be used to grant the necessary permission on the entire database to the new team?
A data engineer needs to apply custom logic to string column city in table stores for a specific use case. In order to apply this custom logic at scale, the data engineer wants to create a SQL user-defined function (UDF).
Which of the following code blocks creates this SQL UDF?